

読者のみなさんはビットコインのトランザクションが着金するのを確認したり、ブロックサイズを確認する際にはどうしていますか?
もちろん本稿のコアな読者の中には「自分のノードで確認するわ!」というユーザーもある程度いらっしゃると思いますが、世の中の大多数のユーザーはウェブで利用できるいずれかのブロックチェーンエクスプローラーを利用しているのではないかと思います。実際、取引所の入出金で送られてくるメールなんかにも、その取引所が選んだエクスプローラーのリンクが貼ってありますよね。
代表的なサービスとしてBlockstream.infoやBlockchain.comなどをよく見かけますが、他にもBlockchairや国産のChainflyerなど多数のエクスプローラーが存在します。これらは差別化ポイントとして、例えばSegwitの利用でどれくらい手数料を節約できたかを表示したり、「ユーザデータを保持しない」というトラストフルな約束をしたり、充実した検索機能などを提供していますが、保証できる形でユーザーのプライバシーを守るものはこれまでありませんでした。
今日はユーザーのプライバシーに重きを置いた新しいブロックチェーンエクスプローラー、Spiralの仕組みについて説明します。
Square Cryptoの新しい名前もSpiralなので紛らわしいですね。本稿で紹介するSpiralの開発が始まったのは2018年だったため当初は名前がかぶっていなかったそうです。ちなみに読み進めるとわかりますが、Spiralはブロックエクスプローラーではなく、読み手のプライバシーを守るDBです!
ブロックエクスプローラーのプライバシー問題
自身がローカルに立てたフルノード以外を使ってトランザクションやアドレスの残高を調べると、方法によってはその検索について何らかの情報が漏洩する場合があります。
まずは通常のブロックチェーンエクスプローラーを利用した場合です。インターネット経由で問い合わせた際に通信の都合でIPアドレスとビットコインアドレスやトランザクションが関連付けられてしまいます。複数の情報を検索すると、それら同士も関連があると見なせてしまいます。IPアドレスを秘匿するために1つ調べるたびにVPNやTorでIPアドレスを変更することもできますが、ミスを犯す余地が比較的大きい上に、タイミングなど副次的な情報から推測されてしまう可能性も残ります。
もちろん、悪いことをしていないならこれらのデータが漏洩していても問題ないのではないか?という考えの方もいるでしょうが、そもそもブロックチェーンエクスプローラーは大半が無料で提供されており、ビジネスとしてデータのマネタイズを狙っている可能性があります。また実際に当局がエクスプローラーの収集したデータを犯罪捜査に利用したことがあるように、このデータは長期的に保持されており、すなわち悪意のある主体にも漏洩・提供されてしまうかもしれないと判断すべきでしょう。
資産に関連する情報である以上、慎重になるのが望ましいです。
次に、かつてライトクライアント方式として主流だったSPVは選択したノードに単純に問い合わせるだけという仕組みで壊滅的にプライバシーがありませんでしたが、後継となったニュートリノ(コンパクトブロックフィルター)はライトクライアントなのに多数のノードからブロックを取得することでプライバシーが非常に強力です。逆に、フルノードほどではありませんが利用にある程度のリソースや時間が必要なのは欠点と言えるかもしれません。また、フルノードではないのでブロックの検証などをビットコインネットワークで行っているわけではありません。
したがって、プライバシー面では自身のフルノード、あるいはニュートリノを使用したライトクライアントで確認するのが圧倒的正解といえますが、Spiralはどのようにブロックチェーンエクスプローラーで過去に類を見ないプライバシーを実現したと主張しているのでしょうか。
Spiralの仕組み
Spiralは準同型暗号を利用して問い合わせの内容を暗号化し、サーバー側ではクエリの内容を把握することなく演算してレスポンスを返すことができるシングルサーバー型のPrivate Information Retrieval (PIR)プロトコルです。どのようにして問い合わせているアドレス等をサーバーに明かさないまま目的のデータを取得しているのでしょうか。
あらかじめ、ラティス暗号(格子暗号)という馴染みのないカテゴリの暗号を使用しているため、暗号関連の処理の詳細が自分にはよくわかりません…。詳しい方、ぜひ教えてください。
まず、データベースの形式から工夫されていて、インデックスを超立方体(正方形や立方体の多次元版)として表現し、すべての次元において座標は{0, 1}のみに限ることで、全体の中でi番目のレコードは(j1, j2, j3, ..., jn) j ∈ {0, 1}という座標で表現できます。クライアントが送るクエリは先頭にiを加えた(i, j1, j2, j3, ...)というベクトルをスカラーRegev暗号化したものです。
サーバーはクエリを暗号文のまま展開してiの部分と(j1, j2, j3, ...)の部分に分けます。iの部分は暗号文のまま行列に変換し、平文のデータベースについて絞り込みをかけるのに利用し、その結果生まれる暗号化された部分集合("サブデータべース")に対してj1 j2 j3などを使った演算で順に絞り込みをかけているようです。要するに、各座標で段階的に絞り込みをかけていて、準同型暗号の特徴として暗号文のまま演算をすることができることを利用しているようです。
最後に出力された暗号化された結果をクライアントに返し、クライアントはこれを復号し平文として利用できる、という流れです。
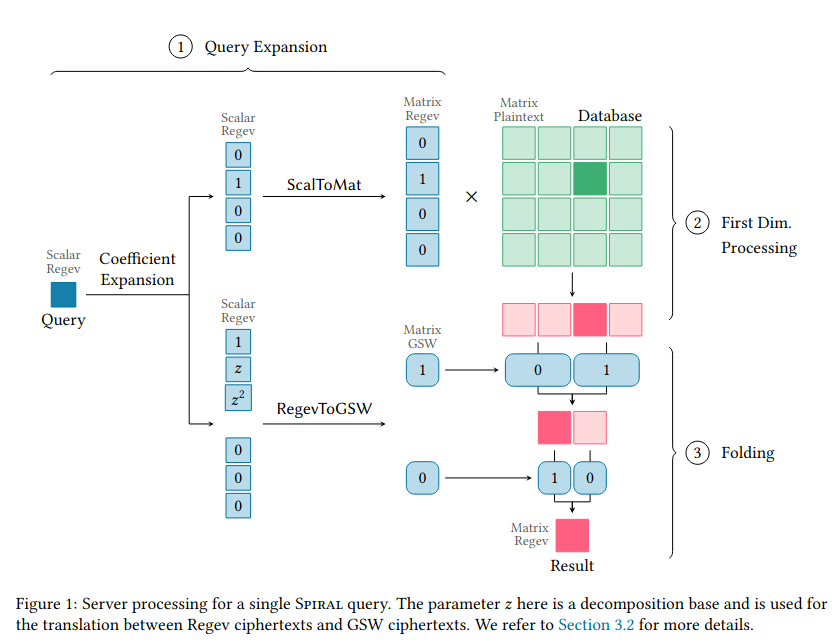
シングルサーバー型のPIRでは一般的に問い合わせを行うクライアント側が数MB程度の変数とクエリをサーバーに送りつけますが、Spiralではこのデータサイズが数十MBある代わりにデータベースのパフォーマンスが良いそうです。
このあたりに細かい実装については、自分には噛み砕いた説明はおろか、理解しきれたわけでもありません。Spiralの本体であるこのPIRプロトコルについてはこちらの論文から確認できるので、暗号学がお好き・得意な方はぜひ挑戦してみてください。
https://eprint.iacr.org/2022/368.pdf
これっていいこと?
もしこのPIRスキームに穴がなく、クライアントもオープンソースの実装に問題がなければ確かに検索した具体的な情報を秘匿したまま結果を受け取ることができそうです。もちろん通常のデータベースよりかなり計算リソースを消費しますが、少なくとも他のシングルサーバー型PIRよりもスループットは高い模様です。サービスとして提供する立場からだと、運用していく際の通信量や計算量のコスト面への影響が気になります。
また、フルノードを動作させる動機を1つ減らしてしまうかもしれないという批判も考えられます。もしフルノードを動かしている動機がプライバシーを保った形で時折自分でトランザクションを調べるための人がいれば、フルノードをやめてSpiralでいいや、という判断をする人も出てくるかもしれません。しかし、同様のトレードオフを提供するニュートリノ形式のライトクライアントがすでに存在しています。また、Spiralが返す結果をトラストする必要がある点に変わりはないので、ブロックチェーンレベルでトランザクションの実在を含めて検証したい場合はノードが必要となることに変わりないでしょう。
ちなみに、この「ライトクライアントが便利になりすぎるとフルノードを立てる人が減ってしまう」という理由でニュートリノを批判しているビットコイナーもいます。変わり種だけど非常に本質を突いた意見をいうことで有名なLukeDashJrです。特に「フルノードめんどくさいからニュートリノでいいや」という風潮を危惧しています。確かに、フルノードと比較してストレージ等の要件も少ないので、コンセンサスへの参加に価値を見出さない限りフルノードの普及にとって障害となる可能性もあるのかもしれません。
SpiralBTC

SpiralのオープンソースのクライアントはRustで記述されており、ブラウザ内で動作するWASMにコンパイルするようです。
GitHub - spiralprivacy/clients
Contribute to spiralprivacy/clients development by creating an account on GitHub.
 spiralprivacy
spiralprivacy以上、Twitterで流れてきたけど話題にしている人が少なく気になったのでSpiralについて調べてみました。仕組みが非常に高度で満足に理解できたわけではありませんが、数十年経てば暗号で本当に色々なことができるようになっているんだろうなと感じますね。
次の記事













読者になる
ビットコイン研究所の新着記事をお届けします。
ディスカッション